
Китайський стартап Z.ai, також відомий як Zhipu AI, представив свою найновішу розробку — модель штучного інтелекту GLM-5.1. Головна сенсація: це не просто чергова LLM, а повноцінний автономний агент з відкритим кодом, здатний виконувати завдання протягом усього робочого дня, пише Venture Beat.
Читайте также: Полювання на темну матерію. У США запускають новий радіотелескоп
Що робить GLM-5.1 особливою?
Основний акцент у розробці зроблено на концепції “8-hour work day”. Якщо звичайні LLM відповідають на конкретний запит, то GLM-5.1 спроєктована для тривалих ітераційних процесів:
- Агентивність (Agentic AI): Модель може самостійно планувати кроки, використовувати зовнішні інструменти (браузер, термінал, API) та виправляти власні помилки без підказок користувача.
- Перемога над закритими моделями: Згідно з бенчмарками, GLM-5.1 обходить Claude 4.6 Opus у завданнях на логіку, програмування та складне міркування.
- Відкритість: На відміну від пропрієтарних моделей від OpenAI чи Anthropic, GLM-5.1 поширюється з відкритими вагами (open-source), що дає розробникам можливість розгортати її на власних потужностях.
Модель GLM-5.1 має 754 мільярди параметрів та контекстне вікно до 202 752 токенів. У той час як інші сучасні моделі, таких як Claude Opus 4.6, досягли верхньої межі продуктивності в 3547 запитів за секунду, GLM-5.1 виконує 655 ітерацій та понад 6000 викликів інструментів на секунду.
Для тих, хто використовує API, Z.ai встановив ціну на GLM-5.1 в розмірі $1,40 за 1 мільйон вхідних токенів та $4,40 за 1 мільйон вихідних токенів. Також доступна знижка на кеш у розмірі $0,26 за мільйон вхідних токенів.
Читайте также: Як український бізнес стає глобальним: в MC.today, The Page, ITC, SPEKA та Highload стартує спецпроєкт «Визнані у світі»
У бенчмарку SWE-Bench Pro, який оцінює здатність моделі вирішувати реальні проблеми GitHub за допомогою запиту інструкцій та контекстного вікна з 200 000 токенів, GLM-5.1 досяг балу 58,4. Щодо контексту, це перевершує GPT-5.4 з 57,7, Claude Opus 4.6 з 57,3 та Gemini 3.1 Pro з 54,2 .
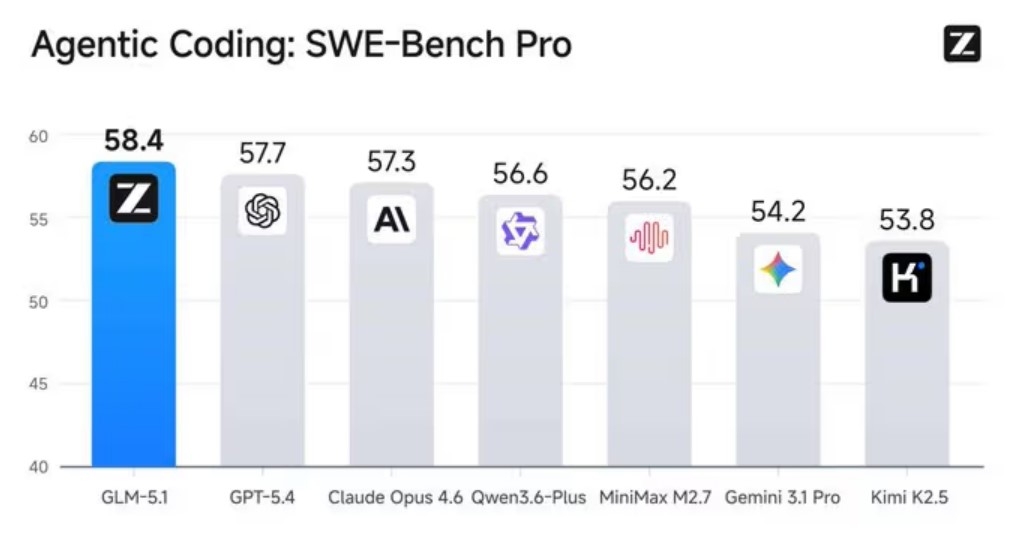
Інші показники GLM-5.1 у порівнянні з конкурентами:
| Категорія | Claude 4 Opus | GLM-5.1 | GPT-5.4 |
| Кодинг (HumanEval) | 84.1% | 88.4% | 87.9% |
| Математика (GSM8K) | 94.2% | 96.5% | 95.8% |
| Довгий контекст (Recall) | 98.1% | 99.9% | 99.2% |
Реліз GLM-5.1 підтверджує тренд на «агентизацію» ШІ. Ми переходимо від ери «запитай-отримай відповідь» до ери «постав задачу — отримай готовий проєкт увечері». Для розробників це означає доступ до інструменту рівня Opus 4 без прив’язки до хмарних сервісів та дорогих підписок.
Нагадаємо, що програмісти — перші в зоні ризику: в Anthropic вже порахували, як швидко вас замінить LLM.
Читайте также: Творець біткоїна. Журналісти NYT стверджують, що викрили особистість Сатоші Накамото
Підписуйтесь на нас у соцмережах: Telegram | Facebook | LinkedIn