
За останній рік кількість LLM-моделей з відкритим кодом, які працюють з українською мовою, зросла на 122% — це найвищий показник серед усіх мов на платформі Hugging Face. Далі йдуть шведська (117%), арабська (89%), турецька (82%) та китайська (75%), пише AI World.
Варто відзначити, що англійська мова все ще домінує за загальною кількістю моделей, на другому місці — китайська. Далі йдуть французька, іспанська та німецька мови. Однак темпи їхнього зростання нижчі, ніж у мов, що стрімко набирають популярність.
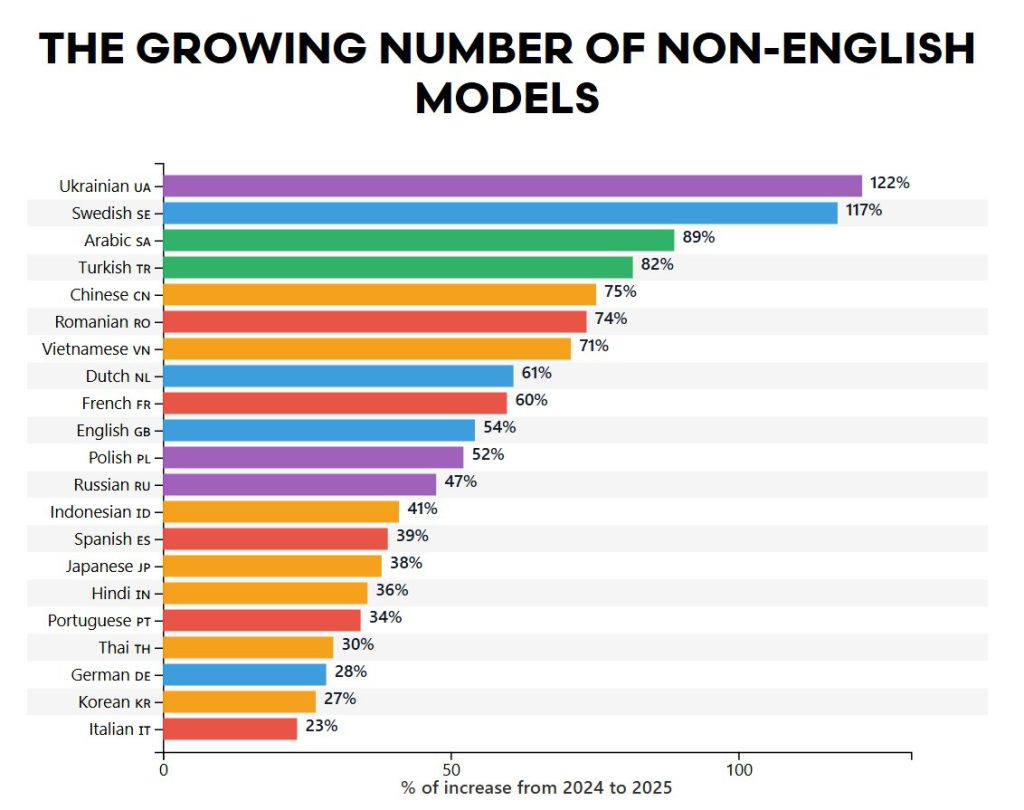
Зростання популярності української, шведської, арабської та інших мов-лідерів, на думку експертів, сигналізує про швидке зростання нових та/або оновлених LLM-моделей. Дані свідчать про те, що імпульс розвитку зміщується в бік мов, які раніше були менш представлені в цій технології, що сприяє більш різноманітній багатомовній екосистемі в рамках штучного інтелекту з відкритим кодом.
Нагадаємо, що українська національна LLM, робота над якою ведеться фахівцями «Київстар» і Мінцифри, базується на відкритій моделі Google Gemma 3. Зі свого боку, Мінцифри відповідає за збір даних для тренування моделі. Спеціалісти «Київстар» візьмуть на себе втілення технічних рішень.
https://highload.tech/uk/ukrayinska-mova-lidyruye-za-tempamy-rozpovsyudzhennya-v-llm-modelyah/